
大模型具备适用于众多场景的泛化能力
大模型的泛化能力是其核心优势之一,使其能够突破单一任务或领域的限制,灵活适配多样化的现实需求。以下是这一能力的关键支撑因素及典型表现:
一、泛化能力的底层逻辑
1、海量数据的隐性知识编码
世界知识的压缩存储:通过万亿级Token的预训练,模型隐式学习了语言结构、常识推理、专业知识(如医学、法律)甚至文化背景,形成覆盖广泛领域的“通用知识库”。
2、参数化的语义空间映射
向量空间的连续性:大模型将离散符号(文字/图像)映射到高维连续空间,相近语义的对象在空间中聚集。这种几何特性使模型能处理开放式问题。
应用:查询扩展——输入“减肥食谱”可联想至“低卡路里”“高蛋白”等关联概念。
3、元学习的自适应机制
快速校准的新场景迁移:微调阶段只需少量样本即可调整参数分布,本质是通过梯度下降在新任务附近寻找最优解边界。
二、跨维度的泛化表现
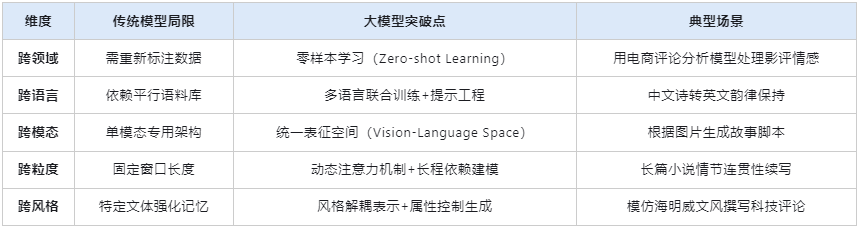
三、实现泛化的关键技术路径
1、自监督学习的涌现效应
无标注数据的威力:通过Masked Language Modeling (MLM)、Next Sentence Prediction (NSP)等任务,迫使模型主动构建语义关联网络。
2、提示工程
指令即接口:通过精心设计的输入模板引导模型行为,无需修改底层参数即可切换任务模式。
进阶技巧:思维链提示(Chain-of-Thought Prompting)显著提升复杂推理性能。
3、检索增强生成(RAG)
外部知识实时注入:结合向量数据库,在生成时动态检索最新信息,解决幻觉问题的同时保持时效性。
效果对比:纯生成式回答准确率约65%,RAG加持后可达90%+。
四、典型行业应用矩阵
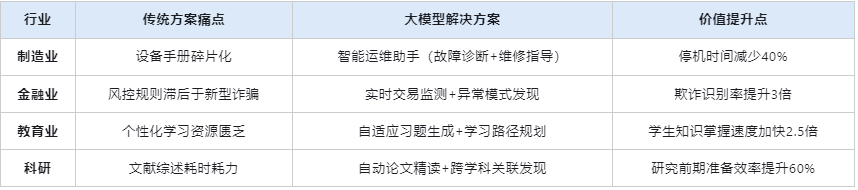
五、泛化能力的边界与挑战
当前限制:
分布外数据脆弱性:对抗样本攻击成功率仍达30%-50%
逻辑链条断裂风险:超过5步的多跳推理错误率急剧上升
价值对齐偏差:不同文化背景下的道德判断一致性不足
改进方向:
引入因果推理模块强化逻辑严谨性
构建跨文化价值观对齐数据集
开发不确定性量化输出机制
大模型的泛化能力本质上是规模化带来的认知涌现现象,其核心价值在于将人工智能从“专用工具”转变为“通用认知接口”。未来随着多模态预训练、持续学习技术的发展,这种泛化能力将进一步突破现有边界,真正实现“举一反三”的机器智能。
- 上一篇:AI大模型的准确定义是什么?
- 下一篇:ai大模型就业门槛高吗?















 400-626-7377
400-626-7377
 录播
录播
 公开课
公开课
 题库
题库
 在线咨询
在线咨询