
学习AI大模型需要从哪里学起?
2025-08-22 09:15:00 | 来源:企业IT培训
学习 AI 大模型可按以下 4 步极简路径 入手,重点突出核心逻辑和实操性:
一、第一步:打牢基础(1-2个月)
必学内容:
数学:线性代数(矩阵运算)、概率统计(贝叶斯定理)、微积分(梯度下降);
编程:Python + PyTorch/TensorFlow(掌握张量操作);
机器学习基础:监督学习、损失函数、过拟合解决方案。
二、第二步:理解大模型原理(1个月)
关键概念:
Transformer架构(自注意力机制、位置编码);
预训练-微调范式(为什么海量数据能让模型“举一反三”);
涌现能力(规模效应带来的推理、创意等意外技能)。
实践:用 Hugging Face 加载 BERT/GPT-2,观察文本生成效果。
三、第三步:动手实践(贯穿全程)
低成本实战方案:
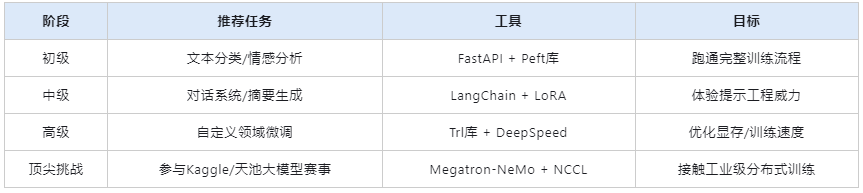
四、第四步:聚焦垂直领域(长期)
差异化方向:
技术纵深:研究 MoE(混合专家)、4D 张量并行等前沿架构;
行业落地:结合医疗/金融/教育场景,设计 Prompt Templete 模板;
伦理安全:学习 RLHF(强化学习微调)、偏见检测过滤技术。
常见误区:
× 一上来就追求参数量大 → ✔️ 从小模型开始理解底层逻辑;
× 只看不练 → ✔️ 每天写代码复现论文小实验;
× 忽视数据处理 → ✔️ 学会用 datasets 库清洗/增强数据。















 400-626-7377
400-626-7377
 录播
录播
 公开课
公开课
 题库
题库
 在线咨询
在线咨询